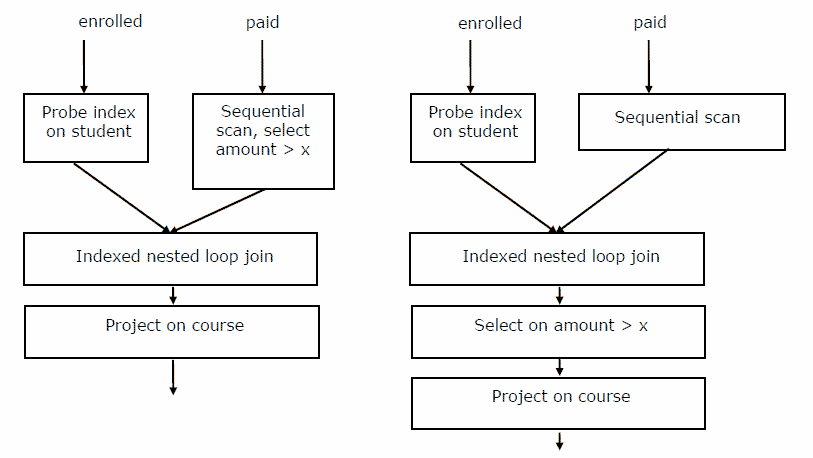
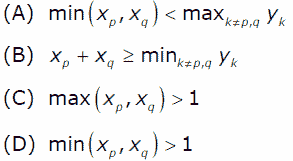Loading
-
337.
-
338.
-
339.
-
340.
Consider the relation account (customer, balance) where customer is a primary key and there are no null values. We would like to rank customers according to decreasing balance. The customer with the largest balance gets rank 1. ties are not broke but ranks are skipped: if exactly two customers have the largest balance they each get rank 1 and rank 2 is not assigned.
Consider these statements about Query1 and Query2.Query1: Query2: select A.customer, count(B.customer)
from account A, account B
where A.balance <=B.balance
group by A.customerselect A.customer, 1+count(B.customer)
from account A, account B
where A.balance < B.balance
group by A.customer
1. Query1 will produce the same row set as Query2 for some but not all databases.
2. Both Query1 and Query2 are correct implementation of the specification
3. Query1 is a correct implementation of the specification but Query2 is not
4. Neither Query1 nor Query2 is a correct implementation of the specification
5. Assigning rank with a pure relational query takes less time than scanning in decreasing balance order assigning ranks using ODBC.
Which two of the above statements are correct? [2 marks]
(A) 2 and 5
(B) 1 and 3
(C) 1 and 4
(D) 3 and 5
asked in Computer Science And Engineering, 2006
View Comments [0 Reply]
-
341.
-
342.